In this series of posts I’m trying some of the ideas in the book Advances in Financial Machine Learning, by Marcos López de Prado. Here I tackle an idea from chapter 5: fractional differencing.
the problem
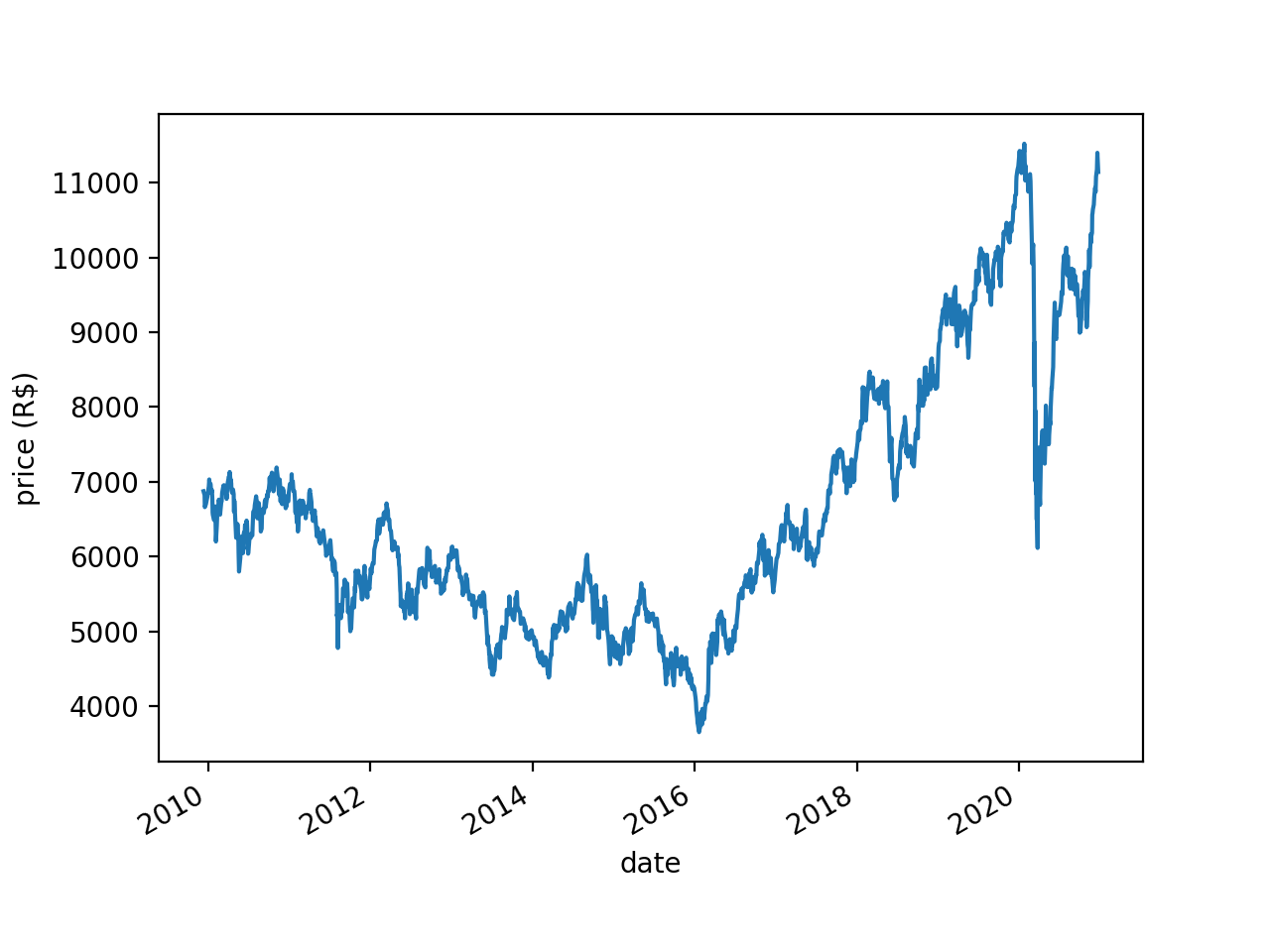
Stock prices are nonstationary - their means and variances change systematically over time. Take for instance the price of BOVA11 (an ETF that tracks Brazil’s main stock market index, Ibovespa):
There is a downward trend in BOVA11 prices between 2010 and 2016, then an upward trend between 2016 and 2020. Unsurprisingly, the Augmented Dickey-Fuller (ADF) test fails to reject the null hypothesis of nonstationarity (p=0.83).
(When I say that the mean and variance change “systematically” in a nonstationary series I don’t mean that in a stationary series the mean and variance are exactly the same at all times. With any stochastic process, stationary or not, the mean and variance will vary - randomly - over time. What I mean is that in a nonstationary series the parameters of the underlying probability distribution - the distribution that is generating the data - change over time. In other words, in a nonstationary series the mean and variance change over time not just randomly, but also systematically. Before the math police come after me, let me clarify that this a very informal definition. In reality there are different types of stationarity - weak, strong, ergodic - and things are more complicated than just “the mean and variance change over time”. Check William Greene’s Econometric Analysis, chapter 20, for a mathematical treatment of the subject.)
Why does stationarity matter? It matters because it can trip your models. If BOVA11 prices are not stationary then whatever your model learns from 2010 BOVA11 prices is not generalizable to, say, 2020. If you just feed the entire 2010-2020 time series into your model its predictions may suffer.
Most people handle nonstationarity by taking the first-order differences of the series. Say the price series is \(\begin{vmatrix}y_{t0}=100 & y_{t1}=105 & y_{t2}=97\end{vmatrix}\). The first-order differences are \(\begin{vmatrix}y_{t1}-y_{t0}=105-100=5 & y_{t2}-y_{t1}=97-105=-8\end{vmatrix}\).
You can take differences of higher order too. Here the second-order differences would be \(\begin{vmatrix}-8-5=-13\end{vmatrix}\). But taking first-order differences often achieves stationarity, so that’s what most people do with price data.
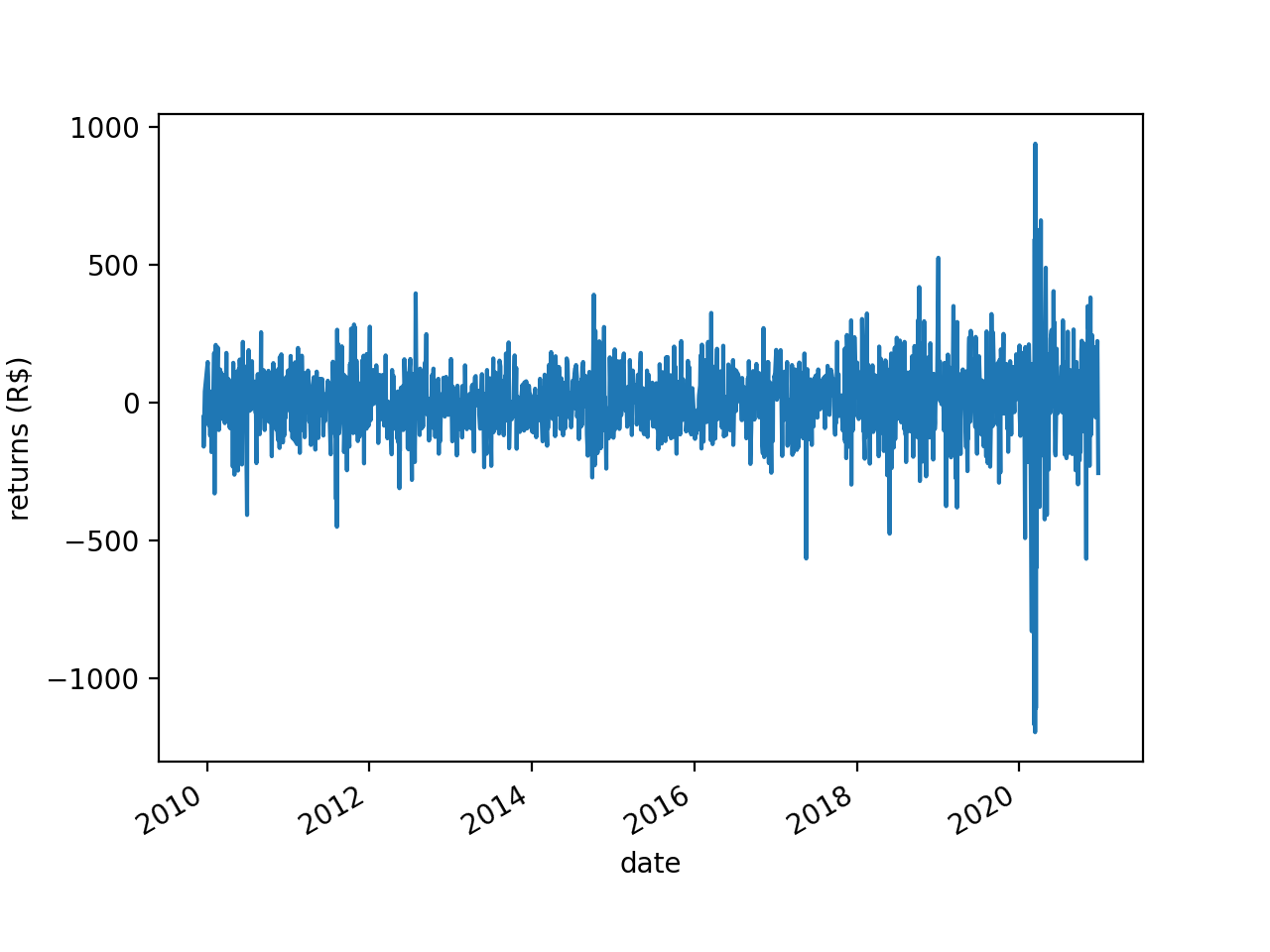
If you take the first-order differences of the BOVA11 series you get this:
This looks a lot more “stable” than the first plot. Here the ADF test rejects the null hypothesis of nonstationarity (p<0.001).
The problem is, by taking first-order differences you are throwing the baby out with the bathwater. Market data has a low signal-to-noise ratio. The little signal there is is encoded in the “memory” of the time series - the accumulation of shocks it has received over the years. When you take first-order differences you wipe out that memory. To give an idea of the magnitude of the problem, the correlation between BOVA11 prices and BOVA11 returns is a mere 0.06. As de Prado puts it (p. 76):
The dilemma is that returns are stationary, however memory-less, and prices have memory, however they are non-stationary.
what to do?
de Prado’s answer is fractional differencing. Taking first-order differences is “integer differencing”: you are taking an integer \(d\) (in this case 1) and you are differencing the time series \(d\) times. But as de Prado shows, you don’t have to choose between \(d=0\) (prices) and \(d=1\) (returns). \(d\) can be any rational number between 0 and 1. And the lower \(d\) is the less memory you wipe out when you difference the time series.
With an integer \(d\) you just subtract yesterday’s price from today’s price and that’s it, you have your first-order difference. But with a non-integer \(d\) you can’t do that. You need a differencing mechanism that works for non-integer \(d\) values as well. I show one such mechanism in the next section.
some matrix algebra
First you need to abandon scalar algebra and switch to matrix algebra. Let’s not worry about fractional differencing just yet. Let’s just answer this: what sorts of matrices and matrix operations would take a vector \(\begin{vmatrix}x_{t0} & x_{t1} & x_{t2} ... x_{tN}\end{vmatrix}\) and return the \(d\)th-order differences of those \(N\) elements?
Say that your price vector is \(X=\begin{vmatrix}5 & 7 & 11\end{vmatrix}\). The first matrix you need here is an identity matrix of order \(N\). If it’s been a while since your linear algebra classes, an identity matrix is a square matrix (a matrix with the same number of rows and columns) that has 1s in its main diagonal and 0s everywhere else. Here your vector has 3 elements, so your identity matrix needs to be of order 3. Here it is:
You also need a second matrix, \(B\). Like \(I\), \(B\) is also a square matrix of order \(N\) with 1s in one diagonal and 0s elsewhere. But unlike in \(I\), in \(B\) the first row is all 0s; the 1s are in the subdiagonal, not in the main diagonal:
Now you raise \(I - B\) to the \(d\)th power. Let’s say you want to find the second-order differences. In that case \(d=2\). Well, if \(d=2\) you could simply multiply \(I - B\) by \(I - B\), like this:
But that is not a very general solution - it only works for an integer \(d\). So instead of multiplying \(I - B\) by itself like that you are going to resort to a little trick you learned back in grade 10:
(In case you’re wondering, \(I^{d-k}\) disappeared because an identity matrix raised to any power is itself, and because an identity matrix multiplied by any other matrix is that other matrix. Hence \(I^{d-k} (-B)^k = I(-B)^k = (-B)^k\))
(Before someone calls the math police: the binomial theorem only extends to matrices when the two matrices are commutative, i.e., when \(XY=YX\). In fractional differencing that is always going to be the case, as \(I\) is an identity matrix and that means \(XI=IX\) for any matrix \(X\). But outside the context of fractional differencing you need to take a look at this paper.)
The binomial expands like this:
\[\sum_{k=0}^{d} \binom{d}{k} (-B)^k = I - dB + \dfrac{d(d-1)}{2!}B^{2} - \dfrac{d(d-1)(d-2)}{3!} B^3 + ...\]
Finally, you discard the first \(d\) elements of that product (I’ll get to that in a moment) and what’s left are your second-order differences. That means your vector of second-order differences is \(\begin{vmatrix}2\end{vmatrix}\). Voilà!
That’s a lot of matrix algebra to do what any fourth-grader can do in a matter of seconds. Very well then, let’s use fourth-grade math to check the results. If your vector is \(\begin{vmatrix}5 & 7 & 11\end{vmatrix}\) then the first-order differences are \(\begin{vmatrix}7-5 & 11-7\end{vmatrix}\) \(=\begin{vmatrix}2 & 4\end{vmatrix}\) and the second-order differences are \(\begin{vmatrix}4-2\end{vmatrix}=\begin{vmatrix}2\end{vmatrix}\). Check!
With matrix algebra you get \(\begin{vmatrix}5 & -3 & 2\end{vmatrix}\) instead of \(\begin{vmatrix}2\end{vmatrix}\) because the matrix operations carry the initial \(5\) all the way through, which means that at some point the difference \(2 - 5\) is computed even though it makes no real-world sense. That’s why you need to discard the initial \(d\) elements of the final product.
If you want to reproduce all that in Python here is the code:
The point of using all that matrix algebra and the binomial theorem is that \((I - B)^d X\) works both for an integer \(d\) and for a non-integer \(d\). Which means you can now compute, say, the 0.42th-order differences of a time series. The only thing that changes with a non-integer \(d\) is that the series you saw above becomes infinite:
\[\sum_{k=0}^{\infty} \binom{d}{k} (-B)^k\]
Finding \(\sum_{k=0}^{\infty} \binom{d}{k} (-B)^k\) can be computationally expensive, so people usually find an approximation instead. There are different ways to go about that and de Prado discusses some alternatives in his book. But at the end of the day you’re still computing \((I - B)^d\), same as you do for integer \(d\) values. Multiply the result by \(X\) and you have your fractional differences. Just remember to discard the first element of the resulting vector (you can’t discard, say, 0.37 elements; you have to round it up to 1).
I thank mathematician Tzanko Matev, whose tutorial helped me understand fractional differencing. If I made any mistakes here they are all mine.
quick note
de Prado arrives at \(\sum_{k=0}^{\infty} \binom{d}{k} (-B)^k\) through a different route that requires fewer steps. Here it is, from page 77:
The way he does it is certainly more concise. But I found that by doing the matrix algebra in a more explicit way, and by including a few more intermediate steps, I understood the whole thing much better.
how to choose d
Alright, so a non-integer \(d<1\) will erase less memory than an integer \(d\geq1\), and now you know the math behind fractional differences. But how do you choose \(d\)? de Prado suggests that you try different values of \(d\), apply the ADF test on each set of results, and pick the lowest \(d\) that passes the test (p<0.05).
Time to work then. de Prado includes Python scripts for everything in his book, so you could simply use that. But here I want to try a more optimized and production-ready implementation. I couldn’t find anything like that for Python. But I found a nifty R package - fracdiff. It’s well documented and it uses an optimization trick that makes it run fast (the optimization is based on a 2014 paper - A Fast Fractional Difference Algorithm, by Andreas Jensen and Morten Nielsen -, with tweaks by Martin Maechler).
I do almost everything in Python these days and I didn’t want to deal with RStudio, dplyr, etc, just for this one thing. So I wrote almost the entire code in Python, and then inside my Python code I have this one string that is my R code, and I use a package called rpy2 to call R from inside Python.
Here is the full code. It reads the BOVA11 dollar bars that I created in my previous post (and saved here for your convenience), generates the plots and statistics I used in the beginning of this post, and finds the best \(d\).
importnumpyasnpimportpandasaspdfromrpy2importrobjectsfrommatplotlibimportpyplotaspltfromstatsmodels.tsa.stattoolsimportadfuller# load data
df=pd.read_csv('bars.csv')# fix date field
df['date']=pd.to_datetime(df['date'],format='%Y-%m-%d')# sort by date
df.index=df['date']deldf['date']df=df.sort_index()# plot
df['closing_price'].plot(ylabel='price (R$)',xlabel='date')plt.show()df['closing_price'].diff().dropna().plot(ylabel='returns (R$)',xlabel='date')plt.show()# check if series is stationary
defcheck_stati(y):y=np.array(y)p=adfuller(y)[1]returnpvalue# prices
check_stati(df['closing_price'].values)# returns
check_stati(df['closing_price'].diff().dropna().values)# check correlation
c=np.corrcoef(df['closing_price'].values[1:],df['closing_price'].diff().dropna().values)print(c)# stringify vector of prices
# (so we can put it inside R code)
vector=', '.join([str(e)foreinlist(df['closing_price'])])# try several values of d
ds=[]d=0got_it=Falsewhiled<1:# differentiate!
rcode='''
library('fracdiff')
diffseries(c({vector}), {d})
'''.format(vector=vector,d=d)output=robjects.r(rcode)# check correlation between prices and differences
c=np.corrcoef(output[1:],df['closing_price'].values[1:])[1][0]# check if prices are stationary
p=check_stati(output)# appendd and c (to plot later)
ds.append((d,c))if(notgot_it)and(p<0.05):print(' ')print('d:',d)print('c:',c)got_it=Trued+=0.01
Running this code you find that the lowest \(d\) that passes the ADF test is 0.29. Much lower than the \(d=1\) most people use when differencing a price series.
With \(d=0.29\) the correlation between the price series and the differenced series is 0.87. In contrast, the correlation between the price series and the return series (\(d=1\)) was 0.06. In other words, with \(d=0.29\) you are preserving a lot more memory - and therefore signal.
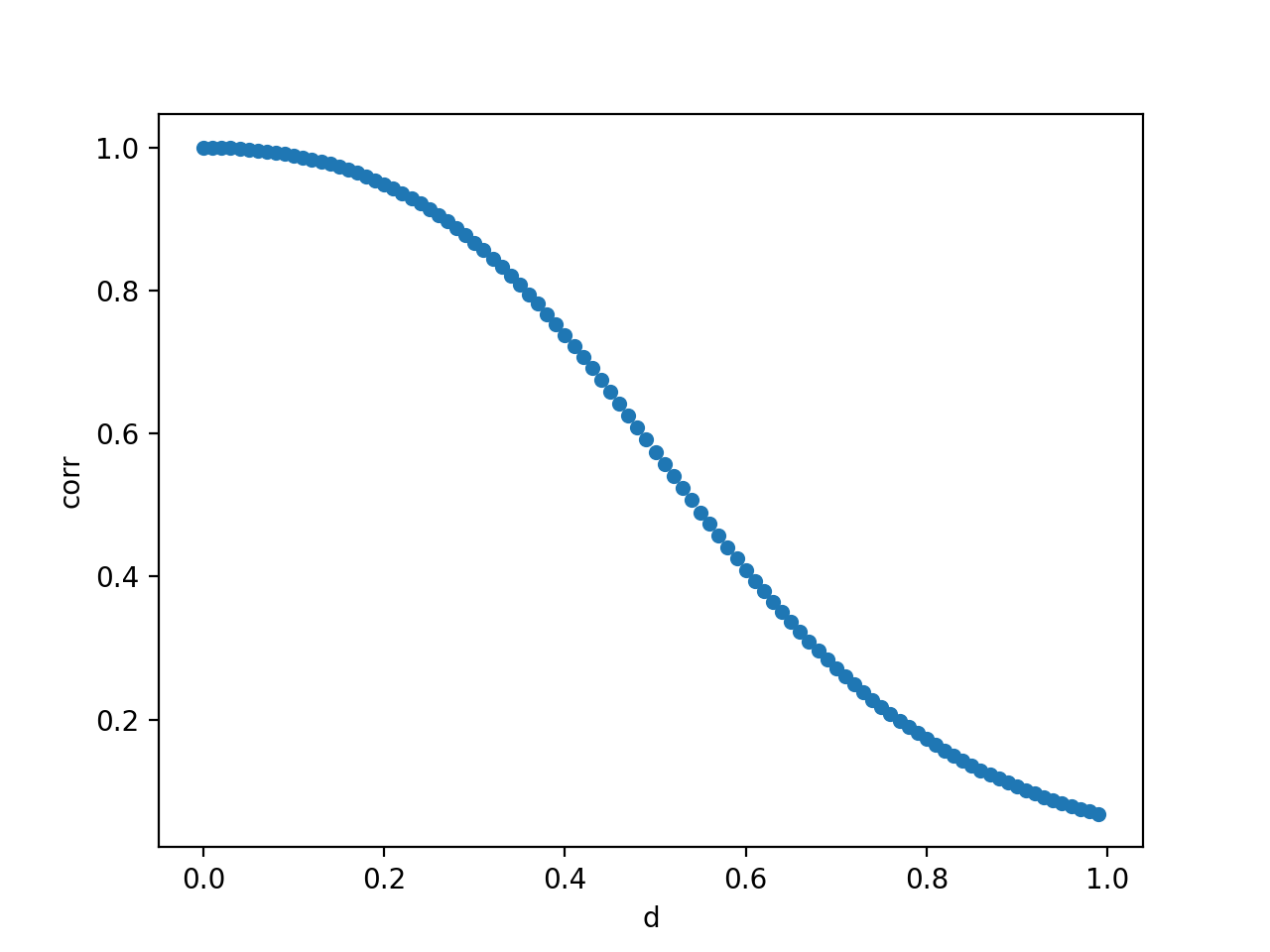
As an addendum, the script also plots how the correlation between prices and \(d\)-order differences decreases as we increase \(d\):
Clearly the lower \(d\) is the more memory you preserve.
I just finished a book called Advances in Financial Machine Learning, by Marcos López de Prado. It’s a dense book and I struggled with some of the chapters. Putting what I learned into practice (and explaining it in my own words) may help me grasp it better, so here it is. (Also, I thought it would be fun to try de Prado’s ideas on data from Brazil.) In this post I put into practice the idea of dollar bars (chapter 2). In the next post I will do fractional differencing (chapter 5). In later posts I want to do meta-labeling (chapter 3), backtesting with combinatorial cross-validation (chapter 12), and bet sizing (chapter 10).
basic idea
We normally think of time series data in terms of, well, time. In most time series each t is a day or a minute or a year or some other measure of time. But t can represent events instead. For instance, instead of t being 24 hours or 30 days or anything like that, it can be however long it takes for 100 people to walk by your house.
Let’s make that (admittedly silly) example more concrete. You wait by the window of your living room and start counting. It takes two hours for 100 people to walk by your house. You note that 28 of them were walking with dogs (let’s say that’s what you’re interested in). That’s it, you’ve collected your first sample: \(y_{t1}\) = 28/100 = 0.28. You start counting again. This time it takes only 45 minutes for another 100 people to walk by your house. 42 of them had dogs. That’s your second sample: \(y_{t2}\) = 42/100 = 0.42. And so on, until you have collected all the samples you want. The important thing to note here is that your t represents a variable amount of time. It’s two hours in the first sample but only 45 minutes in the second sample.
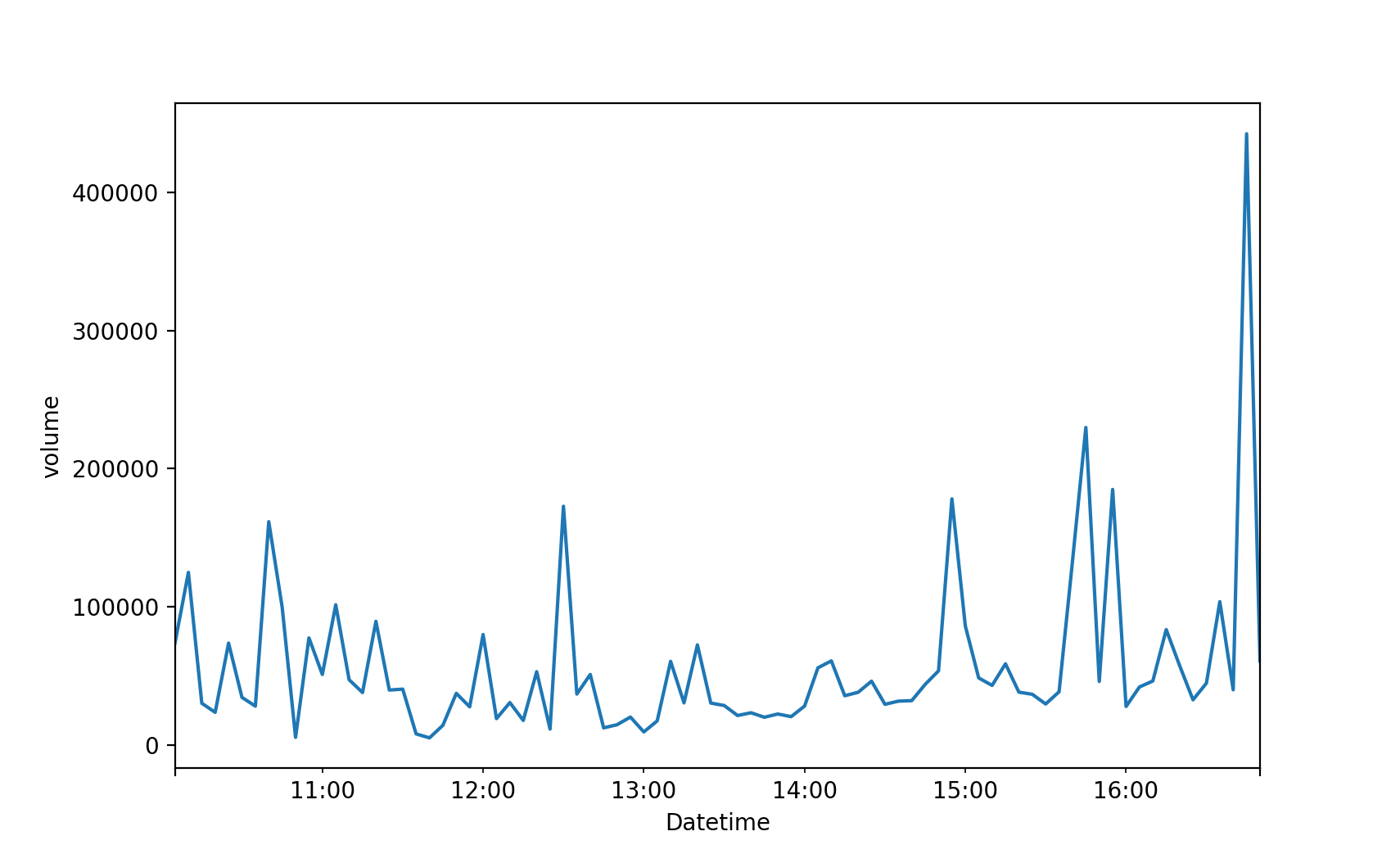
In finance most time series are built the conventional way, with t representing a fixed amount of time - like a day or an hour or a minute. de Prado shows that that creates a number of problems. First, it messes up sampling. The stock market is busier at certain times than others. Consider for example BOVA11, which is an ETF that tracks Brazil’s main stock market index (Ibovespa). This is how BOVA11 activity varied over time on April 12th, 2021:
As we see, some times of the day are busier than others. If t represents a fixed amount of time - 1 hour or 15 minutes or 5 minutes or what have you - you will be undersampling the busy hours and oversampling the less active hours.
The second problem with using fixed time intervals, de Prado says, is that they make the data more serially correlated, more heteroskedastic, and less normally distributed. That may hurt the predictive performance of models like ARIMA. (I wonder whether those problems also hurt the performance of non-parametric models like random forest. The statistical properties of your coefficients can’t be affected when you have no coefficients. But I leave this discussion for another day.)
The solution de Prado offers is that we allow t to represent a variable amount of time - like in my silly example of counting passers-by. More specifically, de Prado suggests that we define t based on market activity. For instance, you can define t as “the time it takes for BOVA11 trades to reach R$ 1 million” (R$ is the symbol for reais, the currency of Brazil.) Say it’s 10am now and the stock market just opened. At 10:07 someone buys R$ 370k of BOVA11 shares. At 11:48 someone else buys another R$ 520k. That’s R$ 890k so far (370k + 520k = 890k). At 12:18, more R$ 250k. Bingo! The R$ 1 million threshold has been reached (370k + 520k + 250k = 1140k). You collect whatever data you are going to use in your model and you have your first sample. Say that you’re interested in the closing price and that it was R$ 100 at 12:18, when the R$ 1 million threshold was triggered. Then your first sample is \(y_{t1}\) = 100. You now wait for another R$ 1 million in BOVA11 trades to happen, so you can have your second sample. And so on.
In reality you don’t “wait” for anything, you look at past data and find the moments when the threshold was reached and then collect the information you want (closing price, volume, what have you).
You can collect more than one piece of information about each sample. Maybe you want closing price, average price, and volume. In that case your \(y_{t1}\) will be a vector of size 3 (as opposed to a scalar). In fact that is more common than collecting a single feature. And finance people often visualize each sample in the form of a “candlestick bar”, like this:
That’s why finance folks talk about “bars” instead of “samples” or “observations”. When the bars are based on fixed time intervals (5 minutes or 1 day or what have you) we call them “time bars”. When they are based on a variable amount of time that depends on a monetary threshold (like R$ 1 million or US$ 5 million) we call them “dollar bars”. (Apparently people call it “dollar bars” even if the actual currency is reais or euros or anything else.)
When you have collected all the samples (“bars”) you want you can use them in whatever machine learning model you choose. Suppose those samples are your y - the thing you want to predict. In that case you will normally want your X - your features - to be based on the same time intervals. In the example above our first sample corresponds to the interval between 10:00 and 12:18 of some day. Say you’re using tweets as one of your features. You will need to collect tweets posted between 10:00 and 12:18 of that same day. Suppose that it took two hours for another R$ 1 million in BOVA11 trades to happen. Then you will need to collect tweets posted between 12:18 and 14:18 of that day. And so on, until you have time-matching X data points for each y data point.
de Prado suggests other types of market-based bars, like tick bars (based on a certain number of trades) and volume bars (based on a certain number of shares traded). Here I’ll stick to dollar bars. Also, to keep things simple I will collect a single feature (closing price) from each sample.
how to make dollar bars
Ok, how do we create dollar bars with real-world data?
First snag: getting the data is hard. Brazil’s main stock exchange, B3, only publicizes daily data. That gives us, for each day and security, highly aggregated information like closing price and total volume. Ideally we would want intraday data - all that same information, but for each 1-minute interval or 5-minute interval. It’s not that I want to do high-frequency trading, it’s just that with intraday data I can train a wider range of models.
(Just to clarify: the goal here is to make dollar bars, not time bars. But I need time bars to build dollar bars.)
Yahoo Finance does give us intraday data (that’s how I got the data for the BOVA11 volume plot above), but only for the last 60 days. That means your models will give a lot of weight to whatever quirks the market experienced over the last 60 days.
You can subscribe to data providers like Economatica, which gives you intraday data going back many years. But that costs about US$ 5k a year. Hard pass. I don’t want to lose money before I even do any trading. I want to lose money after I’ve trained and deployed my models, likethepros.
A friend suggested that I look into trading platforms like MetaTrader. I tried a bunch of them and they do have intraday data, but going back only a couple of weeks. And you can’t download the data, you can only use it online.
So for the time being I settled for the over-harvested, low-frequency data that B3 gives us mortals. More specifically, I downloaded BOVA11 daily data from Dec/2008 through Dec/2020. I saved the CSV file here.
The REAIS column is the amount in R$ of BOVA11 trades each day. That’s what I need to use to build dollar bars here. Which brings us to the question: if I’m defining t as “the time it takes for BOVA11 trades to reach R$ threshold”, what should threshold be? (Let’s call that threshold T from now on.)
Another question is: should T be a constant? On 2008-12-02, when our time series starts, R$ 2.6 billion in BOVA11 shares were traded. But on 2020-12-22, when our time series ends, R$ 59 billion in BOVA11 shares were traded. That’s 20 times more money (not accounting for inflation; by the way I’m completely ignoring inflation in this post, to keep the math simple; if you’re doing this with real $ at stake you probably want to adjust all values for inflation). Suppose we make T a constant and set it to, say, R$ 2 billion. For most of 2010-2020, BOVA11 trade exceeds R$ 2 billion per day. But I don’t have intraday data here, so most days would trigger the R$ 2 billion threshold and generate a new dollar bar. We would basically just replicate the time bars, in which case we gain nothing. On the other hand, if we make T a constant and set it to, say, R$ 200 billion, then the initial years will be reduced to just two or three samples. What to do?
I experimented with several constant values of T, to see what would happen. I tried a bunch of numbers from as low as R$ 300 million to as high as R$ 100 billion. In all cases there was no improvement in the statistical properties of BOVA11 returns, which is the main thing I’m trying to achieve here.
Hence I chose to make T vary over time. For each day in the sample I computed the 253-day moving average of the “dollar” column (REAIS). I chose 253 days because that’s the approximate number of trading days in a year. I then found all the days where that moving average accumulated 25% (or more) growth. Finally, I took each pair of such days and computed the average “dollar” amount (the REAIS column) of the interval between them - and I set T to that average for that interval.
Take for instance 2009-12-10, which is the first day for which we have a moving average (each moving average is based on the preceding 253 days; that means we have no moving averages for the first 253 days of the time series). The 2009-12-10 moving average is R$ 1.5 billion. A 25% growth means R$ 1.875 billion. That amount was reached on 2010-04-29, when the moving average was R$ 1.917 billion. The average REAIS column for the interval between 2009-12-10 and 2010-04-29 is R$ 1.8 billion. Voilà - that’s our threshold for that interval. I did the same for the rest of the time series. The result was the following set of thresholds.
starting date
threshold (billion R$)
2009-12-10
1.8
2010-04-29
2.4
2011-02-09
3.4
2011-08-08
6.2
2011-10-27
6.5
2012-02-07
11.4
2012-04-10
16.4
2012-05-24
10.8
2012-08-29
9.9
2015-09-02
14.7
2016-08-08
18.1
2018-03-01
24.5
2018-10-26
41.2
2019-02-20
41.0
2019-07-25
50.7
2020-01-29
122.0
2020-03-23
111.7
2020-06-12
92.2
2020-10-29
107.5
In the end what I’m trying to do here is to identify the moments when the REAIS column grows enough to need a different T. Now, those choices - 253 days, 25% growth - are largely arbitrary. We could play with different numbers to see how that affects the results. We could also replace the “25% growth” rule with a “25% change” rule, to allow for periods when the stock market goes south. Or we could get more rigorous and use, say, the Chow test to spot structural breaks in the REAIS series. Or - if we had a particular model in mind - we could try to learn those numbers from the data. But for now I’m going with arbitrary choices. Sorry, reviewer 2.
le code
Enough talk, time to work.
There is a Python package called mlfinlab that creates dollar bars and implements other de Prado ideas. But I wanted to do this myself this first time. So here is my code:
importpandasaspdfrommatplotlibimportpyplotaspltfrommatplotlib.patchesimportRectanglefromscipy.statsimportnormaltestfromstatsmodels.stats.diagnosticimportacorr_ljungboxfromsklearn.preprocessingimportStandardScalerfromsklearn.preprocessingimportPolynomialFeaturesfromsklearn.linear_modelimportLinearRegression# load data
df=pd.read_csv('bova11.csv')# fix date field
df['DATAPR']=pd.to_datetime(df['DATAPR'],format='%Y-%m-%d')# sort by date
df.index=df['DATAPR']deldf['DATAPR']df=df.sort_index()# keep only some columns
df_cols=['PREULT',# closing price
'REAIS',# total R$ in BOVA11 trades
'PREMIN',# minimum price
'PREMED',# average price
'PREMAX'# maximum price
]df=df[df_cols]# compute moving averages
window_length=253ma=df['REAIS'].rolling(window_length).mean().dropna()# find days when the moving average
# accumulated 25% growth or more
current_ma=ma[0]cutoffs=[ma.index[0]]foriinrange(len(ma)):ifma[i]/current_ma>1.25:cutoffs.append(ma.index[i])current_ma=ma[i]cutoffs.append(ma.index[-1])# drop days without a moving average
df=df[cutoffs[0]:]# compute thresholds
df['threshold']=Noneforiinrange(len(cutoffs)):ifi==len(cutoffs)-1:breakt0=cutoffs[i]t1=cutoffs[i+1]avg=df[t0:t1]['REAIS'].mean()df.loc[t0:t1,'threshold']=int(avg)# make dollar bars
cumsum=0bars=[]forrowindf.iterrows():threshold=row[1]['threshold']cumsum+=row[1]['REAIS']ifcumsum>=threshold:t=row[0]closing_price=row[1]['PREULT']bars.append((t,closing_price))cumsum=0bars=pd.DataFrame(bars)bars.columns=['date','closing_price']bars.to_csv('bars.csv',index=False)
The result is a total of 1707 dollar bars. They look like this:
date
closing price (in R$)
…
…
2015-12-16
4374
2015-12-17
4374
2015-12-18
4258
2015-12-22
4223
2015-12-23
4275
2015-12-29
4242
2016-01-04
4110
2016-01-06
4050
2016-01-08
3934
2016-01-12
3838
…
…
(Ideally the closing price should be the price you collect the moment your threshold T is reached. But I don’t have intraday data, only daily data. Hence the closing price in each dollar bar here is the closing price of the day each bar ends.)
With time bars we would have 2983 samples, as we have 2983 trading days in our dataset (2008-12-02 through 2020-12-22). By using dollar bars we shrinked our sample size by 42%, down to 1707. That’s a steep price to pay. It’s time to see what we got in return.
The sampling issue has been reduced by construction, there isn’t much to show here. With time bars we would have an equal number of samples from low-activity years, like 2010, and from high-activity years, like 2020. With dollar bars we sample less from low-activity years and more from high-activity years. We still have some degree of over- and under-sampling, since we made T variable, but certainly less than what we would have with time bars.
Have we made BOVA11 returns more normal by using dollar bars? Here is the code to check that:
## check if dollar bars improved normality
# testing and plotting parameters
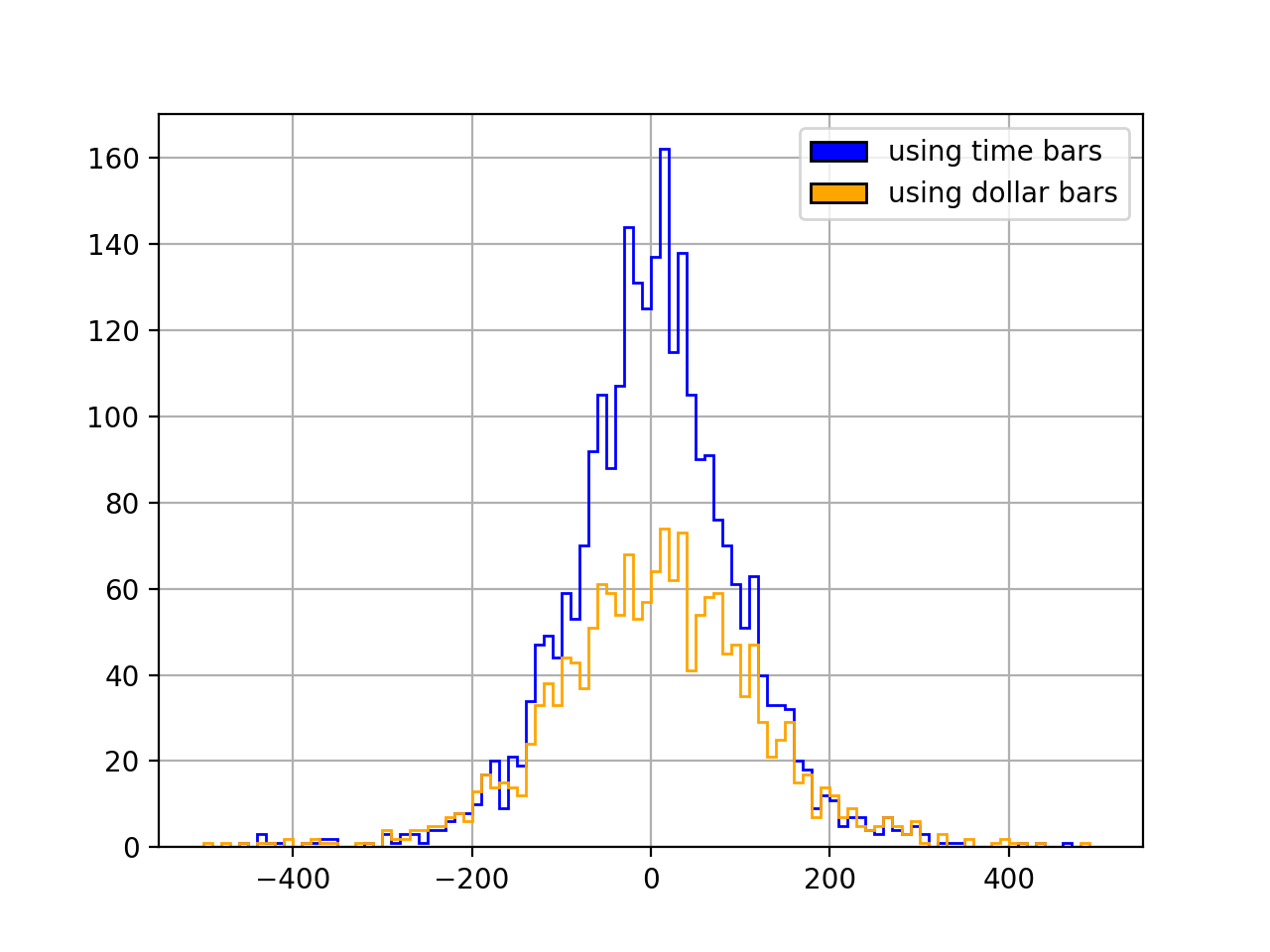
alpha=1e-3rnge=(-500,500)bins=100# time bars
y1=df['PREULT'].diff().dropna().valuesk2,p=normaltest(y1)print('p:',p)ifp<alpha:print('null rejected')else:print('null not rejected')df['PREULT'].diff().hist(bins=bins,range=rnge,histtype='step',color='blue')# dollar bars
y2=bars['closing_price'].diff().dropna().valuesk2,p=normaltest(y2)print('p:',p)ifp<alpha:print('null rejected')else:print('null not rejected')bars['closing_price'].diff().hist(bins=bins,range=rnge,histtype='step',color='orange')# add legend
handles=[Rectangle((0,0),1,1,color=c,ec="k")forcin['blue','orange']]labels=['using time bars','using dollar bars']plt.legend(handles,labels)plt.show()
The null hypothesis here is that the distribution is normal. It is rejected in both cases: neither time bars (p=1.3e-250) nor dollar bars (p=1.5e-125) produce normal returns. But with dollar bars we do get a more normal-looking, less “spiky” distribution:
## check if dollar bars reduced autocorrelation
# set number of lags
lags=10# same as de Prado uses
# time bars
y1=df['PREULT'].valuesac_test=acorr_ljungbox(y1,lags=[lags])print(ac_test)# dollar bars
y2=bars['closing_price'].valuesac_test=acorr_ljungbox(y2,lags=[lags])print(ac_test)
The null hypothesis of zero autocorrelation is rejected in both cases, but the Ljung–Box test statistic is lower with dollar bars (16226) than with time bars (26440). This is similar to what de Prado finds in another of his papers (Flow Toxicity and Liquidity in a High Frequency World, from 2010, on p. 46):
Finally, heteroskedasticity. de Prado (in the same 2010 paper I just mentioned) uses White’s heteroskedasticity test, where you regress your squared residuals against the cross-products of all your features. In the absence of heteroskedasticity the resulting R2 multiplied by the sample size (n) follows a chi-square distribution (with degrees of freedom equal to the number of regressors.)
Now, de Prado has no residuals. He is just building a vector of data to be used in some model later on, same as we are here. So how the heck did he run White’s test? Well, he simply substituted the returns themselves for the residuals. He squared the (standardized) returns and regressed them “against all cross-products of the first 10-lagged series” (p. 46).
I have no idea what the implications of that workaround are. For instance, what if I don’t use an autoregressive model in the end? Maybe with exogenous features I would have no heteroskedasticity to begin with, or maybe I would have heteroskedasticity but the dollar bars wouldn’t help. Heteroskedasticity is a function of the model we are using; as Gujarati notes:
Another source of heteroscedasticity arises from violating Assumption 9 of the classical linear regression model (CLRM), namely, that the regression model is correctly specified. […] very often what looks like heteroscedasticity may be due to the fact that some important variables are omitted from the model. Thus, in the demand function for a commodity, if we do not include the prices of commodities complementary to or competing with the commodity in question (the omitted variable bias), the residuals obtained from the regression may give the distinct impression that the error variance may not be constant. But if the omitted variables are included in the model, that impression may disappear. (Basic Econometrics, p. 367)
Some Monte Carlos might be useful here. We could generate synthetic price data, get the returns, see what happens to the variance of the residuals under different model specifications, and see how heteroskedasticity affects predictive performance. But that’s more work than I’m willing to put into this blog post. Also, de Prado’s algorithms are in charge of Abu Dhabi’s US$ 828 billion sovereign fund. With that much skin in the game he probably knows what he is doing. (On top of that, he has an Erdős 2 and an Einstein 4.) So here I choose to just trust de Prado. Sorry again, reviewer 2.
Here’s the code:
## check if dollar bars reduced heteroskedasticity
# (statsmodels' het_white method returns an
# assertion error, so I had to do it "manually")
defcheck_het(df,price_col):lags=10# same as de Prado used
# get returns
df['DIFF']=df[price_col].diff()# standardize returns
scaler=StandardScaler()df['DIFF']=scaler.fit_transform(df['DIFF'].values.reshape(-1,1))# square standardized returns
df['DIFF']=df['DIFF'].map(lambdax:x**2)# make lags
forlaginrange(1,lags+1):df['LAG_'+str(lag)]=df['DIFF'].shift(lag)df=df.dropna()y1=df['DIFF'].valuesx1=df[[eforeindf.columnsif'LAG'ine]].values# make cross-products
poly=PolynomialFeatures(2,include_bias=False)x1=poly.fit_transform(x1)# regress
reg=LinearRegression()reg.fit(x1,y1)R2=reg.score(x1,y1)returnx1.shape[0]*R2,x1.shape[1]# time bars
test_stat,n=check_het(df,'PREULT')print(test_stat,'w/',n,'degrees of freedom')# dollar bars
test_stat,n=check_het(bars,'closing_price')print(test_stat,'w/',n,'degrees of freedom')
In both cases we reject the null hypothesis of homoskedasticity, but the test statistic is lower with dollar bars (1412) than with time bars (2351). (The degrees of freedom are the same in both cases.) Once more we have a result that is similar to what de Prado found (same 2010 paper as before, same table):
(Just for clarity, what de Prado is reporting in this table is the R2 of White’s regression, not White’s test statistic. But the test statistic is just the R2 multiplied by the sample size, which in de Prado’s case is the same for both the time bar series and the dollar bar series. I report the test statistic in my own results because, unlike him, I have different sample sizes.)
was it all worth it?
That’s a hard question to answer because I’m not training any models here. All I have to go by so far are the statistical properties of the BOVA11 returns, which appear to have improved. But does that mean an improvement in predictive performance? I won’t know until I get to the modeling part. So my answer is “stay tuned!”
Brazilian banks commonly use linear regression to appraise real estate: they regress price on features like area, location, etc, and use the resulting model to estimate the market value of the target property. But Brazilian banks do not test the predictive performance of those models, which for all we know are no better than random guesses. That introduces huge inefficiencies in the real estate market. Here we propose a machine learning approach to the problem. We use real estate data scraped from 15 thousand online listings and use it to fit a boosted trees model. The resulting model has a median absolute error of 8,16%. We provide all data and source code.
Government employees in Brazil are granted tenure after three years of taking their entrance exams. Firing a tenured government employee is all but impossible, so tenure is a big perquisite. But exactly how big is it? No one has ever attempted to estimate the monetary equivalent of tenure for Brazilian government workers. We do that in this paper. We use a modified version of the Sharpe ratio to estimate what the risk-adjusted salaries of government workers should be. The difference between actual salary and risk-adjusted salary gives us an estimate of how much tenure is worth for each employee. We find that the median value of tenure is R$ 4517 for federal government employees, R$ 2560 for state government employees, and R$ 672 for municipal government employees.
I just finished re-reading Mancur Olson’s “The rise and decline of nations”, published in 1982. (According to my notes I had read parts of it back in grad school, for my general exams, but I have absolutely no memory of that.) Olson offers an elegant, concise explanation for why economic growth varies over time. TL;DR: parasitic coalitions - unions, subsidized industries, licensed professions, etc - multiply, causing distributive conflicts and allocative inefficiency, and those coalitions can’t be destroyed unless there is radical institutional change, like foreign occupation or totalitarianism. In a different life I would ponder the political implications of the theory. But I’ve been in a mercenary mood lately, so instead I’ve been wondering what the financial implications are for us folks trying to grow a retirement fund.
the argument
Small groups organize more easily than large groups. That’s why tariffs exist: car makers are few and each has a lot to gain from restricting competition in the car industry, whereas consumers are many and each has comparatively less to gain from promoting competition in the car industry. This argument is more fully developed in Olson’s previous book “The logic of collective action”. What Olson does in “The rise and decline of nations” is to use that logic to understand why rich countries decline.
Once enacted, laws that benefit particular groups at the expense of the rest of society - like tariff laws - are hard to eliminate. The group that benefits from the special treatment will fight for its continuation. Organizations will be created for that purpose. Ideologies will be fomented to justify the special treatment (dependency theory, for instance, is a handy justification for tariffs and other types of economic malfeasance).
Meanwhile, the rest of society will be mostly oblivious to the existence of that special treatment - as Olson reminds us, “information about collective goods is itself a collective good and accordingly there is normally litle of it” (a tariff is a collective good to the protected industry). We all have better things to do with our lives; and even if we could keep up with all the rent-seeking that goes on we’d be able to do little about it, so the rational thing to do is to stay ignorant (more on this).
Hence interest groups and special treatments multiply; competition is restricted, people invest in the wrong industries, money is redistributed from the many to the few. The returns to lobbying relative to the returns of producing stuff increase (more on this). Economic growth slows down. Doing business gets costlier. As Olson puts it, “the accumulation of distributional coalitions increases the complexity of regulation”. Entropy. Sclerosis.
Until… your country gets invaded by a foreign power. Or a totalitarian regime takes over and ends freedom of association. One way or another the distributional coalitions must be obliterated - that’s what reverses economic decline. That’s the most important take-away from the book. Not that Olson is advocating foreign invasion or totalitarianism. (Though he does quote Thomas Jefferson: “the tree of liberty must be refreshed from time to time with the blood of patriots and tyrants”.) Olson is merely arguing that that’s how things work.
I won’t get into the empirical evidence here. The book is from 1982 so, unsurprisingly, Olson wasn’t too worried about identification strategy, DAGs, RCTs. If the book came out today the reception would probably be way less enthusiastic. There are some regressions here and there but the book is mostly narrative-driven. But since 1982 many people have tested Olson’s argument and a 2016 paper found that things look good:
Overall, the bulk of the evidence from over 50 separate studies favors Olson’s theory of institutional sclerosis. The overall degree of support appears to be independent of the methodological approach between econometric regression analysis on growth rates versus narrative case studies, publication in an economics or a political science journal, location of authorship from an American or European institution, or the year of publication.
can Olson help us make money?
There isn’t a whole lot of actionable knowledge in the book. We don’t have many wars anymore:
I mean, between 2004 and 2019 Iraq’s GDP grew at over twice the rate of Egypt’s or Saudi Arabia’s. And between 2002 and 2019 Afghanistan’s GDP grew at a rate 36% faster than Pakistan’s. But that’s about it. A Foreign-Occupied Countries ETF would have a dangerously small number of holdings.
And there aren’t many totalitarian regimes in place:
A Dear Leader ETF would also be super concentrated. (Not to mention that it would contain North Korea and Turkmenistan.)
In any case, GDP growth and stock market growth are different things. Over the last five years the S&P500 outgrew the US GDP by 83%. Conversely, the annualized return of the MSCI Spain was lower than 1% between 1958 and 2007 even though the annualized GDP growth was over 3.5% in that same period.
So, country-wise there isn’t a lot we can do here.
What about industry-wise?
Olson’s book is about countries - it’s in the very title. But his argument extends to industries. Olson himself says so when he talks about the work of economist Peter Murrell:
Murrell also worked out an ingenious set of tests of the hypothesis that the special-interest groups in Britain reduced the country’s rate of growth in comparison with West Germany’s. If the special-interest groups were in fact causally connected with Britain’s slower growth, Murrell reasoned, this should put old British industries at a particular disadvantage in comparison with their West German counterparts, whereas in new industries where there may not yet have been time enough for special-interest organizations to emerge in either country, British and West German performance should be more nearly comparable.
In other words, new industries will have fewer barriers to entry and other organizational rigidities. This seemingly banal observation, which Olson saw as nothing more than a means to test his theory, may actually explain why we don’t have flying cars.
Back in 1796 Edward Jenner, noting that milkmaids were often immune to smallpox, and that they often had cowpox, took aside his gardener’s eight-year-old son and inoculated the boy with cowpox. Jenner later inoculated the boy with smallpox, to see what would happen, and it turned out that the boy didn’t get sick - the modern vaccine was invented. Now imagine if something like the FDA existed back then. We probably wouldn’t have vaccines today, or ever.
It’s the same with the internet, social media, Uber, just about any new industry or technology: at first the pioneers can do whatever they want. But then parasitic coalitions form. They can form both outside the new sector and inside it. Taxi drivers will lobby against Uber. Uber will lobby for the creation of entry barriers, to avoid new competitors - incumbents love (the right type of) regulation. Both sources of pressure will reduce efficiency and slow growth.
Investment-wise, what does that mean? That means it will become a lot harder for, say, ARK funds to keep their current growth rate. ARK funds invest in disruptive technologies - everything from genomics to fintech to space exploration. They are all new industries, with few parasitic coalitions, so right now they’re booming. (Well, they may also be booming because we’re in a big bull market.) But - if Olson is right - as those industries mature they will become more regulated and grow slower. ARK will need to continually look for new industries, shedding its holdings on older industries as it moves forward.
In short: Olson doesn’t help us pick particular countries to invest in, and he doesn’t help us pick particular industries to invest in, but he helps us manage our expectations about future returns. Democratic stability means that fewer of us die in wars and revolutions, but it also means that buying index funds/ETFs may not work so well in the future. Democratic stability - and the parasitic coalitions it fosters - means that today’s 20-year-old kids may be forced to pick stocks if they want to grow a retirement fund. (Though if you’re not Jim Simons what are your chances of beating the market? Even Simons is right only 50.75% of the time. Are we all going to become quant traders? Will there be any anomalies left to exploit when that happens?)
Or maybe when things get bad enough we will see revolutions and wars and then economic growth will be restarted? Maybe it’s all cyclical? Or maybe climate change will be catastrophic enough to emulate the effects of war and revolution? Maybe we will have both catastrophic climate change and wars/revolutions?
but what if the country has the right policies?
Olson gives one policy prescription: liberalize trade and join an economic bloc. Free trade disrupts local coalitions, and joining an economic bloc increases the cost of lobbying (it’s easier for a Spanish lobby to influence the national government in Madrid than the EU government in Brussels). But policy is endogenous: the decision to liberate trade or join an economic bloc will be fought by the very parasitic coalitions we would like to disrupt. And if somehow the correct policy is chosen, it is always reversible - as the example of Brexit makes clear. Also, not all economic blocs are market-friendly. Mercosur, for instance, has failed to liberalize trade; instead, it subjects Argentine consumers to tariffs demanded by Brazilian producers and vice-versa. (I have no source to quote here except that I wasted several years of my life in Mercosur meetings, as a representative of Brazil’s Ministry of Finance.)
So it won’t do to look at the Heritage Foundation’s index of economic freedom and find, say, the countries whose index show the most “momentum”. One day Argentina is stabilizing its currency, Brazil is privatizing Telebrás. Latin America certainly looked promising in the 1990s. Then there is a policy reversal and we’re back to import-substitution. You can’t trust momentum. You can’t trust economic reform. You can’t trust any change that doesn’t involve the complete elimination of parasitic coalitions. And even then things may decline sooner than you’d expect - Chile is now rolling back some of its most important advances.
what if ideas matter?
In the last chapter of the book Olson allows himself to daydream:
Suppose […] that the message of this book was then passed on to the public through the educational system and the mass media, and that most people came to believe that the argument in this book was true. There would then be irresistible political support for policies to solve the problem that this book explains. A society with the consensus that has just been described might choose the most obvious and far-reaching remedy: it might simply repeal all special-interest legislation or regulation and at the same time apply rigorous anti-trust laws to every type of cartel or collusion that used its power to obtain prices or wages above competitive level.
That sounds lovely, but it’s hard to see it happening in our lifetimes. Even if ideas do matter the Overton window is just too narrow for that sort of ideas. It’s probably The Great Stagnation from now on.