This just came out and I wrote one of the chapters. The book is meant for people who did math-heavy PhDs and are considering non-academic careers. It should help them realize that if they know what a p-value is then they can do a lot more than please journal editors and teach bored undergrads; they can use their quant skills to have impact in the real world (and make a lot more money than their academic counterparts). If you check it out let me know what you think.
Brazilian banks commonly use linear regression to appraise real estate: they regress price on features like area, location, etc, and use the resulting model to estimate the market value of the target property. But Brazilian banks do not test the predictive performance of those models, which for all we know are no better than random guesses. That introduces huge inefficiencies in the real estate market. Here we propose a machine learning approach to the problem. We use real estate data scraped from 15 thousand online listings and use it to fit a boosted trees model. The resulting model has a median absolute error of 8,16%. We provide all data and source code.
How much insider trading happens in Brazil’s stock market? Previous research has used the model proposed by Easley et al. [1996] to estimate the probability of insider trading (PIN) for different stocks in Brazil. Those estimates have a number of problems: i) they are based on a factorization that biases the PIN downward, especially for high-activity stocks; ii) they fail to account for boundary solutions, which biases most PIN estimates upward (and a few of them downward); and iii) they are a decade old and therefore based on a very different market (for instance, the number of retail investors grew from 600 thousand in 2011 to 3.5 million in 2021). In this paper I address those three problems and estimate the probability of insider trading for 431 different stocks in the Brazilian stock market, for each quarter from October 2019 to March 2021.
Getting historical intraday financial data can be a pain, especially for non-US markets. If you have deep pockets you can simply buy the data you need, but for retail investors the cost is prohibitive. If you want historical transaction-level data for the Brazilian stock market, for instance, TickData will sell it to you for about US$ 65000. Hard pass. What to do?
I recently learned about an app called MetaTrader. MetaTrader gives you real-time stock price charts. It is popular with people who do technical analysis - people who buy and sell equities based on certain chart patterns (like a “head and shoulder formation”, for instance). I’ve never bothered with technical analysis and I guess that’s why MetaTrader had escaped my radar until now.
The important thing is: many brokers pay MetaTrader so that their clients can access it, and MetaTrader has historical intraday data for whatever market(s) each broker operates in.
I checked and it turns out that my broker in Brazil has one such deal with MetaTrader. I got a username and password, downloaded the app, and started exploring.
If you’re only interested in a couple of equities you can export the data manually. Go to the View menu and click Symbols.
A new window will open:
The “BMF” and “Bovespa” you see in that window are the names of two exchanges in Brazil (they’ve been merged into a single exchange called B3 but I guess MetaTrader is keeping the old names for now). You will see different names, depending on where your broker operates.
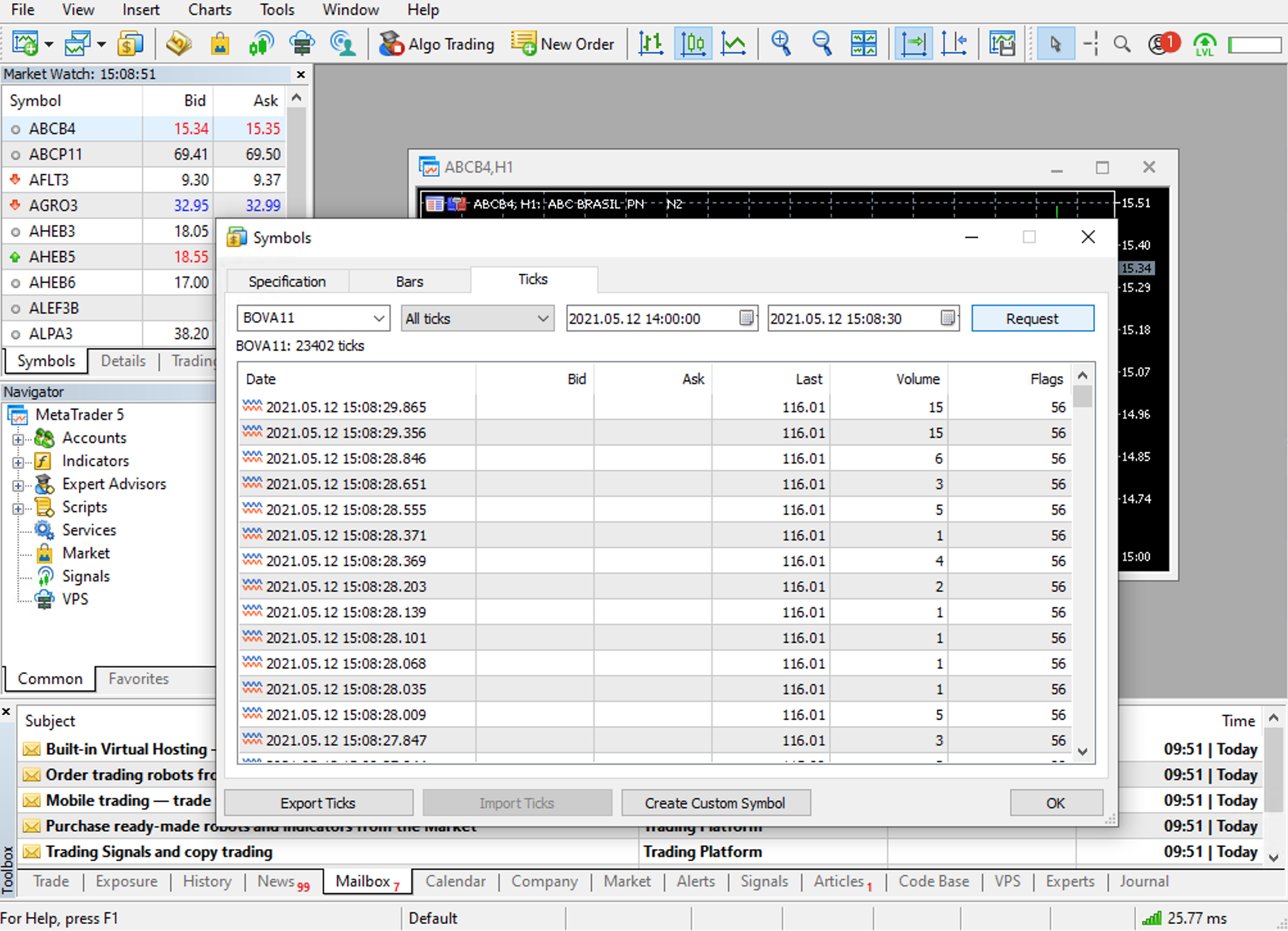
Say you’re interested in tick data. Just click on the Ticks tab, enter the ticker for the equity you want, and click Request. Here I am requesting tick data for BOVA11, an ETF that tracks Brazil’s main stock market index:
The Export Ticks button lets you save the data in a CSV format.
If you want time bars then go to the Bars tab instead.
The data you get depends on what your broker provides MetaTrader. I explored a bit and it looks like lower frequency data requests yield longer time series. When I request 1-minute BOVA11 bars I only get a year or so of data, but when I request 5- or 10-minute BOVA11 bars I get a few more years. That’s a far cry from the 13 years of data TickData sells, but for us DIY wannabe quants that’s enough to play around a bit. And, well, it costs zero dollars. (With TickData you’d need to pay US$ 6750 to access a single year of tick data from Brazil).
That’s all there is to it - if you are only interested in a couple of equities. But what if you want data for hundreds of equities? Or for all equities? Fortunately, MetaTrader has a nice Python API that you can access after pip installing the MetaTrader5 package.
Unfortunately, the MetaTrader5 package only works on Windows. If you want to use it on a macOS or Linux machine you’ll need Wine. I have access to a Windows machine so that wasn’t a problem for me.
Here is a minimal working example of how the Python API works. This snippet requests tick data (trade ticks only - no bid/ask ticks) for BOVA11 between 2021-01-01 and 2021-01-07 and then saves the results in a CSV file. Before you run this script you need to launch the MetaTrader app and log into it using the credentials your broker gave you.
importpandasaspdimportMetaTrader5asmt5fromdatetimeimportdatetime,timedelta# connect to MetaTrader 5
ifnotmt5.initialize():print('initialize() failed')mt5.shutdown()# request tick data
ticks=mt5.copy_ticks_range('BOVA11',datetime(2021,1,1),datetime(2021,1,7),mt5.COPY_TICKS_TRADE)ticks=pd.DataFrame(ticks)ticks.to_csv('BOVA11_ticks.csv',index=False)# shut down connection to MetaTrader 5
mt5.shutdown()
If you want data for more equities just loop through the corresponding tickers. If that’s a lot of tickers there is a method symbols_get() that will return all tickers. For instance, the tickers for Brazilian ordinary stocks always have four letters followed by the number 3 - PETR3, HYPE3, etc. If you want only ordinary stocks you can use symbols_get() and then filter out any string that doesn’t have five characters or doesn’t end in 3.
One issue I’ve come across is that sometimes the API returns no data even though a manual search (using the GUI) shows that there is data. That doesn’t happen often but when it does it’s always with highly liquid equities, so I’m guessing if there is too much data to return you get nothing instead. So you may want to loop through shorter intervals - months instead of quarters, or weeks instead of months, or days instead of weeks, depending on how much data you’re requesting.
Another thing to keep in mind is that MetaTrader generates temp files for your requests and they are big as heck. It got to the point where my hard drive ran out of space. I had to use Python’s os to delete those temp files on-the-fly. They are saved to AppData/Roaming/MetaQuotes/Terminal/HASH/bases/BrokerID/ by default. If you want them to be saved elsewhere you have to move the MetaTrader installation folder to the new location and then execute it using cmd, with AlternateLocation/terminal64.exe /portable The temp files will be stored in AlternateLocation/Bases/BrokerID/
Here is a more complete example:
importosimporttimeimportcalendarimportpandasaspdimportMetaTrader5asmt5fromdatetimeimportdatetime,timedelta# connect to MetaTrader 5
ifnotmt5.initialize():print('initialize() failed')mt5.shutdown()# get connection status and parameters
print(mt5.terminal_info())# get MetaTrader 5 version
print(mt5.version())# path to CSVs
path_to_csvs='C:/Users/YourUserName/Desktop/ticks/'# path to temp data (so we can delete it)
path_to_tmp='C:/Users/YourUserName/AppData/Roaming/MetaQuotes/Terminal/HASH/bases/BrokerID/'# get all B3 tickers
symbols=mt5.symbols_get()# keep only tickers for ordinary stocks
tickers=[]forsymbolinsymbols:ticker=symbol.nameifnotticker[:4].isalpha():continueif(len(ticker)==5)and(ticker[-1]=='3'):tickers.append(ticker)# month-years to scrape
months={2019:(10,11,12),2020:range(1,13),2021:(1,2,3)}# loop through tickers
start=time.time()fori,tickerinenumerate(tickers):# loop through month-years
foryearinmonths.keys():formonthinmonths[year]:print(' ')print(i,'of',len(tickers),ticker,year,month)# set date range
t0=datetime(year,month,1)last_day=calendar.monthrange(year,month)[1]t1=datetime(year,month,last_day)# request tick data
ticks=mt5.copy_ticks_range(ticker,t0,t1,mt5.COPY_TICKS_TRADE)ticks=pd.DataFrame(ticks)# log if results are empty
ifticks.shape[0]==0:withopen('log.txt',mode='a')asf:l=ticker+','+str(year)+','+str(month)+'\n'f.write(l)print('empty DataFrame:',l)continue# persist
print(ticks.shape[0])ticks['time']=pd.to_datetime(ticks['time'],unit='s')ticks.columns=['ticktime','bid','ask','last','volume','time_msc','flags','volume_real']ticks.to_csv(path_to_csvs+ticker,index=False)# don't over-request
time.sleep(2.5)# delete tmp files
forfnameinos.listdir(path_to_tmp+ticker+'/'):try:os.remove(path_to_tmp+ticker+'/'+fname)except:pass# how long did it take?
elapsed=time.time()-startprint('it took',round(elapsed/60),'minutes')# shut down connection to MetaTrader 5
mt5.shutdown()
Finally, a word about the “flags” column (you can see it in the BOVA11 screenshot above). That column encodes a lot of information. For instance, it encodes whether the tick refers to a buy-initiated trade or to a sell-initiated trade. But it’s not as simple as “56 means buy-initiated” or anything like that. It took me some doing to learn how to interpret the flags. Turns out they are bit masks. To extract the information encoded in each flag you need to do a bunch of bitwise operations. For instance, to tell whether a given tick represents a buy- or sell-initiated trade you need to pass the flag through a function like this:
defbuy_or_sell(flag):'''
see https://www.mql5.com/en/forum/75268
for explanation on MetaTrader flags
'''if(flag&32)and(flag&64):return'both'elifflag&32:return'buy'elifflag&64:return'sell'
MetaTrader uses 32 to encode “buy-initiated” and 64 to encode “sell-initiated”. Say the flag for a given tick is 56. The bitwise operation 56 AND 64 returns 0. That means the tick does not refer to a sell-initiated trade. But the bitwise operation 56 AND 32 returns 32. That means the tick refers to a buy-initiated trade. (In some rare cases the tick refers to a trade that was simultaneously initiated by buyer and seller.) The flag 212, on the other hand, returns opposite results: 212 AND 32 returns 0 and 212 AND 64 returns 64 - in other words, a tick with the flag 212 refers to a sell-initiated trade.
Here is information on everything else that each flag encodes.
This is it. Let me know if there are other sources of intraday data I should check out. What are the cool kids using?
I just finished Jack Schwager’s Unknown Market Wizards. It’s a collection of interviews with retail traders. The interviewees follow different approaches - fundamental, technical, quant, social media mining - but they share similar attitudes and Schwager does a good job hypothesizing how these attitudes might relate to trading outcomes. On top of that, Schwager is a superb interviewer and he shows the world of retail traders in a way that’s neither the aggregate statistics of academic papers nor the get-rich-quick Youtube ads selling day trading courses. I’ve always thought of traders as people who somehow missed Burton Malkiel’s A Random Walk Down Wall Street. Schwager showed me a much more interesting picture. Here are some highlights:
skill vs luck
The eleven traders in the book all have spectacular performances. We’re talking annualized returns of 20%-300%, sometimes for several years. But the book doesn’t give us enough data to know whether those performances are the result of skill or mere luck. If you ride a big bull market it’s possible to have stellar returns with random bets. Bitcoin has yielded an annualized return of 558% since May 2015. That doesn’t make early Bitcoin adopters market wizards (though some of them certainly are).
“The magnitude by which the traders in this book outperformed market benchmarks over long periods (typically, decade-plus) cannot simply be explained away as ‘luck.’”, Schwager writes (p. 348). To give only two examples, Daljit Dhaliwal never had a negative year and he was profitable in 95% of quarters, and Pavel Krejcí had positive returns in 93% of all quarters. But to tell luck from skill we would need to know who was trading what when and what each monthly return was, then follow an approach like Fama & French’s where they compare actual returns with simulated returns. Schwager doesn’t give us a data appendix, so we can’t do that. (The data is not Schwager’s to publicize but he could have run the numbers himself and showed us the results.)
It’s tempting to guess which of the eleven traders are skilled (as opposed to merely lucky) based on the narrative each of them offers. Several of them emphasize the importance of updating your beliefs based on new information (so that you can limit your losses if the market turns against you, for instance), but without overcorrecting. Some also emphasize the importance of sizing your bets according to how confident you are. These attitudes are typical of Philip Tetlock’s superforecasters.
But they are just narratives. Each trader (except for the one quant guy) is describing his mental model of himself. That mental model is probably a better trader than the actual human behind it. And at times the narratives sound wishy-washy: “I am using my feelings as an input to trading.” (p. 110), “The human emotions that we feel can be used as a signal source.” (p. 193), that sort of thing. (Though for the most part the narratives are pretty Tetlockian.)
In short, it is possible that Schwager selected eleven very lucky people and then spent hours listening to after-the-fact rationalizations. But even if that’s the case (which I don’t know) the book is still immensely enjoyable if you are curious about retail trading.
people who are always wrong can make (you) money
My favorite strategy is one of Jason Shapiro’s:
I watch Fast Money religiously at 5 p.m. EST every day. I can’t tell you how much money I’ve made off of that show. […] There is one guy on the program named Brian Kelly, who I have now watched for years. He is wrong by such a larger percentage than random that it is hard to believe. I will never have a position on if he is recommending it. (p. 69)
I don’t know if that really works or if Shapiro is just rationalizing but I love the idea and now I want to find Fast Money transcripts and backtest it.
shrinking anomalies
Several of the interviewees believe that anomalies are disappearing.
Peter Brandt, talking about how things have changed for chartists since the 1980s:
Large long-term patterns no longer work. Trendlines no longer work. Channels no longer work. Symmetrical triangles no longer work. (p. 37)
Richard Bargh:
there are also far fewer opportunities now than back in 2013 and 2014. Back then, many things were still relatively new, like quantitative easing and forward guidance. There was more uncertainty about what the central banks were going to do and how they were going to do it. Whereas now, the markets have central banks so nailed down that there is not as much opportunity to make money on central banks as there once was. The markets now are good at pricing in events before they happen. I make money by pricing in a surprise, and with fewer surprises, there are fewer opportunities. (p. 100)
Amrit Sall:
increased market automation and high-frequency-trading algorithms have made execution harder and eroded my edge on some very short time frame strategies. (p. 142)
Daljit Dhaliwal:
It is no longer possible to trade for the initial move off the headline because the algos will make the trade before I can. (p. 157)
It makes sense. Data is cheaper, processing power is cheaper, machine learning courses are free; it would be odd if anomalies didn’t disappear.
patience
Another common theme is the importance of waiting for the right trade.
Richard Bargh says you should have a side project:
One thing about event-driven trading is that if there isn’t an event to trade, there is nothing to do, and it is really boring. You can feel like you’re wasting your life. […] I have found that I trade much better when I have a side project. If I have nothing else to do but trade events, and there are no events to trade, my mind runs wild. I need to focus my attention on something; otherwise, I will focus on the wrong things. (p. 104)
Bargh again:
Trading to earn a consistent amount steadily may be an admirable goal, but it is not a realistic one. Market opportunities are sporadic. […] If you try to force consistent profitability, you will be prone to take suboptimal trades, which will often end up reducing your overall profitability. (p. 177)
Amrit Sall:
There will be periods in the markets where opportunities dry up, and there will be nothing to do. In those nothing periods, if you are looking for something to do, that is when you can create real damage to your account. (p. 129)
Daljit Dhaliwal:
you don’t have to take every potential trade. You can wait for a trade where everything lines up in your favor. (p. 154)
Chris Camillo articulated it best:
Looking back, I think a big part of my success when I went back to trading was my ability to look past the noise and be patient. I wasn’t in the industry. It wasn’t my job, and I wasn’t under any pressure to trade. I could go six months without a trade, and I didn’t have to answer to anybody. (p. 239)
(The other day I was listening to a podcast interview with a quant fund manager and he emphasized that “we work a lot, we don’t just create a bot and then go to the beach”. It’s odd that people choose to invest in a quant fund but then expect constant human activity - as long as the fund is making you money what do you care that the staff is at the beach? But apparently investors want busy managers.)
What Camillo says ties in with Marsten Parker’s advice:
Don’t quit your day job. (p. 287)
If you have a stable source of income it’ll probably be easier to avoid overtrading.
TickerTags
One of my favorite interviews in the book is the one with Chris Camillo. He mines social media looking for information that might help him anticipate stock price movements. Like when there was an outbreak of E. Coli in Chipotle stores:
Chipotle had become famous for having long lines at lunchtime. Chipotle was such a trendy brand that it was common for people to tweet about having lunch there. They would also frequently tweet about how they were waiting in line at Chipotle. I was able to gauge real-time foot traffic by monitoring word combinations, such as “Chipotle” plus “lunch,” and “Chipotle” plus “line,” in online conversations. Almost overnight, the mentions of these word combinations dropped by about 50%.
I imagine NLP folks at quant shops reading about Camillo and his Chipotle trade. There they are, fine-tuning BERT and whatnot, and then Camillo with his hard-coded bigrams makes a killing.
Camillo made a business out of that: he created TickerTags, a company that tracks word combinations on social media. As Camillo says, tracking conversations is a way to “go even earlier than trasactional data” (like credit card information).
TickerTags doesn’t seem to have been successful with hedge funds though:
Hedge fund managers want something repeatable and systematic. They wanted to know how often this approach would generate tradable information with high conviction. I couldn’t give them a hard answer. (p. 253)
That is a recurrent theme throughout the book. The trader “knows” that the strategy works but somehow can’t put a number on it. Peter Brandt says if the market closes in a new high or in a new low on a Friday then it is likely to keep moving in that direction on Monday and early Tuesday. But when asked if he ever checked that pattern he replies “I have never statistically analyzed it.” Hhmm.
the one quant guy
Marsten Parker is the only quant in the group. He touches on an interesting point:
I’ve always struggled with how to distinguish between a routine drawdown and a system that has stopped working. (p. 278)
Last month I finished reading Marcos López de Prado’s Advances in Financial Machine Learning. de Prado talks about how the death of a strategy can actually be a good thing:
For instance, a mean-reverting pattern may give way to a momentum pattern. As this transition takes place, most market participants are caught off guard, and they will make costly mistakes. This sort of errors is the basis for many profitable strategies, because the actors on the losing side will typically become aware of their mistake once it is too late. Before they accept their losses, they will act irrationally, try to hold the position, and hope for a comeback. Sometimes they will even increase a losing position, in desperation. Eventually they will be forced to stop loss or stop out. Structural breaks offer some of the best risk/rewards. (p. 249)
de Prado suggests a number of tests to identify structural breaks - for instance, testing if the cumulative forecasting errors look random. I wonder if that’s the sort of thing Parker is doing. He doesn’t get into technical details though, other than to mention that he’s learned about overfitting the hard way, that he uses parameter stability as an indicator of robustness, that your errors will be more serially correlated in real life than in your backtest, and that it’s best to have several simple strategies than one over-optimized strategy. (Also: “The more strategies you run, the easier it is emotionally to turn one off.”, p. 286.)
I love this:
if I knew everything I do now, I might never have tried trading in the first place. (p. 286)
I imagine all the state-of-the-art models that RenTec or AQR must be training, the hordes of Mensa Ph.D.s they recruit, the deep pockets they have to buy credit card data or Twitter’s Firehose, I think of Quantopian’s failure, and it sounds impossible to me that any sort of artisanal, DIY quant approach could succeed. But maybe Parker isn’t just lucky. His interview updated my priors a bit.
loving your trade
The appeal of trading is that it is something you can do on your own - no employees, no bosses, no clients, no students, no reviewers, no drama, no politics, no culture wars.
Jason Shapiro:
I had six people working for me, and I hated it. I didn’t like managing people and being responsible for their success. (p. 72)
Pavel Krejcí:
I wanted to find something where the success or failure would depend only on me, not my colleagues, my boss, or anybody else. If I make money, that’s great; if I lose money, it’s my mistake. (p. 320)
That’s happinness almost by definition.
Alright, any more quotes and I’ll probably get a lawsuit so I’m stopping here. Go buy the book.